Get Free Trial Week Developer Access, Try Before You Hire. Click Here to Claim Now

AI-Ready Software Architecture: What to Build Today for Future Scale

AI-ready software architecture treats machine learning as a core component, not an add-on. Data pipelines, storage, inference and observability are built together from day one rather than bolted as an afterthought. Teams adopting this approach early gain a significant advantage, enabling AI features to reach production sooner. Technical debt is avoided, making scaling simpler and predictable.
TL;DR
- AI readiness is an architecture decision. It is not a tooling or headcount option.
- Data pipelines, model observability and inference design determine if AI features will reach production or stay in staging.
- Most enterprise AI failures trace back to retrofitting. Systems built for reporting cannot serve real-time inference without an architectural redesign.
- Mitigation runs in parallel with delivery with a phased approach. No big-bang rewrite is needed.
- ROI comes from deployment speed and regression recovery time. It isn’t measured via model accuracy benchmarks alone.
It is Q2 2026. Your competitor ships a personalization feature in 3 weeks. But your team estimates six months for the same feature. The gap isn’t talent. It’s architecture.
Your data layer wasn’t designed for low-latency inference. According to architecture readiness audits conducted by ManekTech, teams with AI-native data layers reach production 60-70% faster than those retrofitting legacy pipelines.
54% of enterprise AI projects fail to move from pilot to production due to these infrastructure gaps. True AI-readiness isn’t decoration via API calls. It is a foundational decision you make at inception.
This article provides you with a framework to budget for and build systems supporting real-time inference and scale.
Market Context and Business Urgency
Infrastructure gap is measurable while cost of delay is compounding. These four data points showcase business urgency.
- According to BCC Research (Dec 2025), the AI infrastructure market will grow from $158.3B in 2025 to $418.8B by 2030 (21.5% CAGR).
- 54% of enterprise AI projects never reach production; at least 40% cite infrastructure gaps as the primary concern.
- ML time on data prep is about 60-80%. This amount is spent on data engineering, not model development
- Teams with legacy architectures spend 30-40% of their sprints on infrastructure workarounds.
All these reasons point towards infrastructure improvements before proceeding with AI.
Why AI-Ready Is an Architecture Decision, Not a Tooling Decision?
Adding an LLM API call to an existing service becomes an AI decoration. It doesn’t define AI-readiness. True readiness means latency budgets, feedback loops and data flows designed into the system from inception. Most scaling failures traceback to decisions made in 2023 or even 2024, when AI was treated as a feature.
Who This Article Is For?
This article is written for three main types of audiences. CTOs and VPs of engineering who are evaluating whether their architecture can support AI products at scale. It is also for technical founders building new systems with a need to avoid retrofitting from day one. Lastly, it is for enterprise architectures who are responsible for modernization roadmaps, including ML pipelines and real-time inference.
Diagnostic questions, readiness scorecard and build-versus-buy tables throughout are designed to support concrete decisions.
Five Architectural Decisions That Separate AI-Scale Systems from AI-Struggling Systems
Every architecture review we have conducted across enterprise AI engagements surfaces the same five decisions. They are the primary determinants of delivery speed, reliability and cost at scale. These are not just decisions. This is the point where choosing wrong compounds the hardest and corrects the slowest.
Each decision below follows the same structure. What it is, what it costs you to make the wrong choice and what a correct architecture looks like. You will also get a diagnostic question that an engineering lead should be able to answer in 60 seconds.
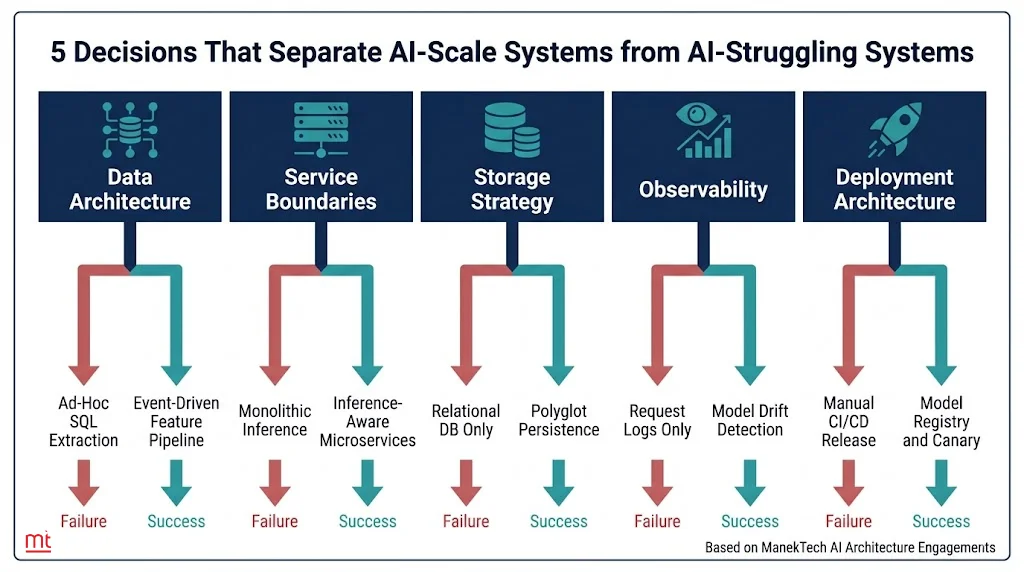
Decision 1: Data Architecture: Structured Pipelines vs. Ad-Hoc Extraction
The choice here is between an event-driven feature pipeline and ad-hoc SQL queries. Event-driven produces versioned and labelled feature vectors at ingestion time. Ad-hoc extracts features on demand from production databases.
Most teams start with ad-hoc as it needs no new infrastructure. They end up paying for that decision in terms of engineering time for the rest of the project. When your data scientists and ML engineers spend about 60-80% of their time on data extraction, it doesn’t offer model improvements. Instead, it produces slower and expensive projects with an accuracy similar to project that started with clean data.
The correct architecture offers clean and versioned feature vectors that can be consumed by ML training jobs and live inference endpoints. This means one pipeline, and one feature definition that’s served identically across both stages.
For EU deployments, feature pipelines must be designed with data residency boundaries. They should comply with GDPR Article 44 transfer restrictions.
Factor | Ad-hoc SQL Extraction | Event-driven Feature Pipeline |
Data availability | On-demand query; results vary per run | Near real-time. Vectors are ready for ingestion |
Feature consistency | Different engineers can extract same feature differently | Single versioned definition reused across customers |
ML engineer onboarding | Requires a data engineering ticket to get clean data | Self-serve access to feature registry on day one |
Production DB load | Training runs query on live production database | Pipeline decoupled. No shared load |
Audit and compliance | Feature lineage unclear. Training runs hard to reproduce | Full lineage traceable to source event. |
Diagnostic: Can your ML team access clean and labelled dataset for any core business entity in under 30 minutes without opening a data engineering ticket? This diagnostic will measure your architectural friction. If answer is no, your team is mostly operating in reactive state. Every new AI feature is delayed by manual data. Passing this 30-minute threshold means your data layer is built to expose signals to inference pipeline in real-time, allowing you to ship features in weeks instead of months. |
Decision 2: Service Boundaries: Monolith vs. Inference-Aware Microservices
The decision determines whether inference calls sit inside a monolith or within a dedicated service. Monolith approach embeds the model into the request handlers. The dedicated service approach isolates them using their own latency SLAs, scaling policies and fallback behaviour. The choice looks minor. Under load, you will know if AI feature takes down the application or degrades quietly on its own.
A single 5-second P99 inference spike in a synchronous monolith propagates across every request handler sharing that thread pool. At 1000 concurrent users, the blast radius covers the entire application. The incident is already open by the time the model recovers.
The correct architecture treats AI inference as a first-class service. It has its own scaling policy, timeout contract, queue-based load leveling pattern and graceful degradation path. This is true when model endpoint is unavailable.
Queue-based load leveling pattern decouples inference request submission from result retrieval. This prevents inference latency from propagating to user-facing request threads.
Diagnostic: If your primary model endpoint experiences a 5-second P99 spike, which user facing flows break. How many concurrent users are affected while the spike persists? This diagnostic will measure blast radius. If the answer covers more than 1-2 flows, inference isn’t isolated. It is a load-bearing architecture within the application. A spike in one model shouldn’t be the reason for timeout for unrelated users. Passing this means, your inference layer with SLA, scaling policy and fallback path activates before thread pool saturates. |
Decision 3: Storage Strategy: Traditional Databases vs. AI-Native Storage Layer
Most teams store everything in the relational database till similarity query starts timing out. The fix then is no longer a configuration change. It is an architecture migration under production pressure.
Cosine similarity UDFs on PostgreSQL work fine at 10,000 records. However, at 10 million, a single query may exceed 30 seconds. It locks shared buffers. Unrelated queries at this instance collapse. This failure is structural and index tuning won’t fix it.
The decision is whether semantic retrieval, embedded storage and similarity search can live inside relational database or inside purpose-built vector store with dedicated approximate nearest neighbor index. Most teams don’t make a formal decision. They inherit it from whoever wrote the first similarity query against the production database.
Polygot persistence is the correct design. A relational database can handle transactional truth and structured queries. A vector store will handle sematic retrieval. The semantic cache layer will handle repeated and high-cost inference results using TTL-aware invalidation. Each layer does what it’s built for. Nothing performs beyond its design.
pgvector on existing PostgreSQL carries a near-zero marginal infrastructure cost. It serves workloads under 500,000 vectors. Move to Qdrant, Weaviate, or Pinecone when you have above 5 million vectors or the SLA needs sub-100ms P99 similarity search.
Diagnostic: Where in your current system do you compute vector similarity? At what record count does that query begin to degrade response time? This diagnostic locates structural risk for you. If you cannot answer the record count question, your team hasn’t hit the ceiling yet but it exists. Knowing the number lets you plan migration on your terms. |
Decision 4: Observability: Request Logging vs. Model Behaviour Monitoring
Standard APM tools catch service downtime and HTTP errors. They are blind to models that have quietly shifted their output distribution by 15%. The endpoint will deliver 200 OK. Every dashboard will show green. But the product is quietly failing.
The first signal occurs in the form of customer support ticket. It means failure was live for days before anyone on the engineering team knew about it. This isn’t an edge case. It is the default outcome for teams running AI workloads on traditional monitoring infrastructure.
The correct architecture to choose is dedicated AI observability layer. It covers both prompt and response logging as well as latency distribution, model version and output quality signals. They are fed back to training pipeline and semantic anomaly alerting. These don’t replace your existing APM. It will sit alongside it and handle what APMs don’t detect.
This is a compliance requirement for regulated deployment. Under the EU AI act article 12, high-risk AI systems must maintain logs to trace system operations post deployment. HTTP logs don’t offer this. Structured prompt and response logging with caller identity and output classification would provide this.
Diagnostic: If your model’s output quality is degraded by 15% from today, what is the earliest your team would detect it. What is the mechanism you would use? This diagnostic measures the detection lag. If the answer is waiting for user complaints, your observability layer monitors wrong signals. The goal is to detect degradation from dashboard in hours. Not as support queue in days. |
Decision 5: Deployment Architecture: Manual Releases vs. Model Lifecycle Management
Deploying model updates using CI/CD pushes it to 100% production traffic immediately. When the update degrades output quality, there is no fast path back. Recovery means identifying bad versions, locating previous artefacts, rebuilding and redeploying it. That sequence usually takes 2-6 hours under incident conditions.
The correct architecture would use versioned model registry with quality gates, canary routing and shadow mode evaluation. Shadow mode runs the new model against real traffic before user sees output. Canary advances traffic in tiers using automated quality gate at each step. Registry rollback restores previous version in under 15 minutes. This needs no code redeployment or artefact rebuild.
Capability | Standard CI/CD | Model Registry + Canary |
Traffic on update | 100% immediately | 5% → 20% → 50% → 100%. Quality gate at each tier |
Rollback mechanism | Redeploy previous code. Takes 2-6 hours | Registry pointer swap; under 15 minutes |
Pre-production validation | None on real traffic | Shadow mode against live traffic before user exposure |
Quality gate | Manual or none | Automated, model blocked if metric threshold is breached |
Version traceability | Check deployment logs | Registry holds every version with quality history. |
Diagnostic: How long does it take to roll back a bad model update to previous stable version? What percentage of production traffic is affected during that window? Recovery exposure is measured through this diagnostic. The longer the rollback takes, the higher its traffic percentage. It will have a bigger business impact in case of bad model update. If the answer is hours and 100%, there is no safety net for your deployment architecture. |
The AI-Ready Stack: What Each Layer Must Be Able to Do
True AI-readiness isn’t achieved through superficial API integrations. It is a foundational architectural decision you make at inception. Here are the specific patterns needed to transition from legacy anti-patterns to scalable ready state.
Layer Comparison Table: Legacy vs. AI-Ready
The contrast between a traditional software pattern and AI-native architecture is stark. AI ML Development Services Engineering leaders must move away from batch-based systems. Manual monitoring isn’t enough. You must shift to event-driven architectures using isolated and autonomous environments. This is required for scale.
Each layer mentioned here is defined by what they must do for AI workloads to run reliably at production scale. Legacy anti-patterns are named explicitly. Understanding why they fail is important to know what you must build.
Quick Glance Table: Legacy vs AI Ready Layer Comparison
Layer | Legacy Anti-Pattern | AI-Ready Target | Named Pattern | Cost Tier | Primary Risk of Staying Legacy |
Data Ingestion | Nightly batch ETL. Data available T+24 hours | Streamining event pipeline. Feature data in near real-time | Event sourcing, CDC | Low to mid | Model trained on scale features. Real-time inference impossible. |
Feature Store | Ad-hoc queries to production database per training run | Centralized feature registry versioned | Feature registry pattern | Low to high | Training/serving skew guaranteed. Model unpredictable in production |
Inference Layer | Sync API call inline with user request | Async inference service with latency SLA | Queue based load leveling | Low to mid | P99 spikes cascade, AI features turn to reliability liabilities |
Storage/Retrieval | Relational database for all query types | Polygot: relational + vector store + semantic cache | Polyglot persistence | Near zero to USD 5k per month | Cosine similarity on SQL destroys performance over 1 million records |
Model Serving | Single endpoint, manual deployment, no traffic splitting | Model registry, canary and shadow mode, auto rollback | Blue-green or canary deployment | Low to mid | Bad model update hits 100% traffic with no recovery path |
Observability | Request logs, error rate, latency monitoring | Prompt or response logging, quality metrics, drift detection | AI observability pattern | Low to mid | Model degradation invisible till users report problems |
Security/Access | API key management, standard RBAC | Prompt injection defense, output sanitization, access audit logs | Zero trust for AI endpoints | Integrated | LLM used as attack surface, sensitive data leaked with prompt extraction. |
Every single risk in the primary risk column is invisible till it becomes expensive for you. Stale features don’t increase errors. Training and serving skews don’t send out alerts.
A model update hitting 100% traffic looks identical to one with clean data till the support tickets start coming in. These are all silent failures. You can prevent them with the right architecture.
Key Insight: In the architecture readiness audits we have conducted since 2023, the feature store and observability layers are consistently absent for enterprise AI systems. Teams have inference and storage. They rarely have versioned features or model-specific monitoring. These gaps account for production AI incidents we see during intake. |
The Feature Store: The Most Underbuilt Layer
A feature store isn’t your data warehouse. A data warehouse would answer business questions. But a feature store is the contract between your data and model team.
Without feature store all ML projects re-extracts the same features using different logic. Two engineers will write their own version for customer recency feature. The model trains using one version and serves via the other. The output drifts in a way nobody can explain and debugging takes weeks. Rebuilding the pipeline from scratch is the only fix to this issue.
Features are defined once in the feature store. They are versioned, tested and served identically during training and inference time. Whether the model is running a training job on last month’s data or serving a live user request, it sees the same signal. This consistency makes model behaviour predictable in production.
Where to start depends on your team. Feast (feast.dev) works best for cloud-native teams that want full control with an engineering capacity to operate it. Tecton is managed option for enterprise teams that need production SLAs and cannot absorb key-person risk during custom implementations.
The cost difference for both cases is significant. Feast is free while Tecton starts at $80,000 per year. The right choice depends on whether you have budget or engineering capacity constraint. (Notes: Some Enterprise pricing typically starts from $100K–$250K+)
The Inference Layer: Designing for Latency Budgets Before Model Selection
Most teams select a model and then discover whether it fits their latency requirements. That’s a backward sequence.
You must define the latency budget first. The formula is straightforward.
Total user facing SLAs = Inference Time + Retrieval Time + Rendering Time. |
Consider a product search flow with 200ms total budget. This leaves 80ms for inference, 60ms for retrieval and 60 ms for rendering.
A model with P99 inference at 150ms fails that budget before it serves even one user. No amount of optimization can fix this model.
Use the async-first rule to any model that exceeds 300ms. Queue the inference and return the result when it is ready. Don’t make the user-facing thread wait. You can add a semantic cache for repeat queries. Caching embeddings with similarity threshold would reduce total model API calls by 30-60% (GPT Semantic Cache on arXiv). This is true for high-repeat query patterns. It directly reduces inference cost and average latency.
Key Insight: The most common latency budget we notice at ManekTech is teams define P50 target and never measure P99. A model that performs well on average and collapses at peak is not meeting the budget. This is a hiding problem inside aggregate metrics. Always design your model for P99, especially for user-facing AI flows. |
Security Layer: AI-Specific Threats Not Addressed by Standard RBAC
Standard access control was designed for human accessing systems. Not for models being prompted by users. The threat surface is different for both.
These are the aspects your security layer needs when handling specific AI workloads.
- Prompt Injection: User input will manipulate model instructions. The fix is input sanitization, output validation before results and system prompt hardening. Narrow models are harder to exploit than general purpose ones. Use an explicit output format and tight scope for your system prompt.
- Data Exfiltration via Mode: When your fine-tuned models memorize PII from training data, you need this. To ensure this fix, you need differential privacy during training and output filtering inside serving layer.
- Model Access Audit Logs: Every model is logged with caller identity, input hash and output class. this is mandatory for regulated industries under NIST AI RMF govern function and EU AI Act Article 12. It’s not optional for compliance-sensitive deployments.
If your current security stops at API key management and RBAC, your AI system may create an unguarded attack surface. The cost of adding prompt injection defences before launch is a sprint.The cost of data exfiltration incident after launch is higher.
You Cannot Pause Delivery to Rebuild: Here Is How to Migrate While Shipping
Timing is the most common reason why AI architecture work is delayed. The team’s roadmap and capacity is full. There is no sprint available or infrastructure. This objection is valid if migration must stop delivery. But that’s doesn’t happen.
A phased approach runs architectural improvement alongside feature shipping. You don’t stop building. Instead, you stop building on the wrong foundation.
You must recognize the four traps derailing modernization efforts before proceeding with migration.
The Four Migration Traps That Stall AI Modernization
Here are the four migration traps you should know.
Trap 1 The Big Bang Rewrite
Your team decides to rebuild the entire data along with serving layer before shipping a single AI feature. Business stops waiting. They ship the feature on top of the old architecture. The technical debt compounds and rewrites never finish. Eventually, old system doesn’t retire.
Trap 2 Greenfield Isolation
The AI system is built as a separate application. It has no connection to production data. The app won’t see real traffic patterns or be incrementally validated. When it’s time to migrate, the gap between isolated system and production reality becomes wider. Bridging this gap proves to be expensive.
Trap 3 Tooling-first Adoption
Teams select vector database, serving platform and observability tool before defining the workload these tools must serve. Tool capability isn’t a substitute for architectural design. They remain underutilized as the architectural foundation needed for these tools was never built.
Trap 4 The Velocity Trap
AI features are shipped for the existing architecture to meet the roadmap deadlines. Technical debts accumulate quickly. No single decision creates this trap. It happens gradually as your team uses one shortcut at a time. By the time they begin noticing, the migration has become a multi-year program.
ManekTech sees these patterns in majority of AI engagement intakes. Recognizing the trap is the first step out of this.
The Phased Migration Model: HowTo Schema Target
Migration doesn’t need you to stop delivery. It needs you to sequence the work properly. Each phase runs in parallel with your existing roadmap. A feature is shipped at every phase. The architecture gets closer to AI-ready without stopping delivery with every phase.
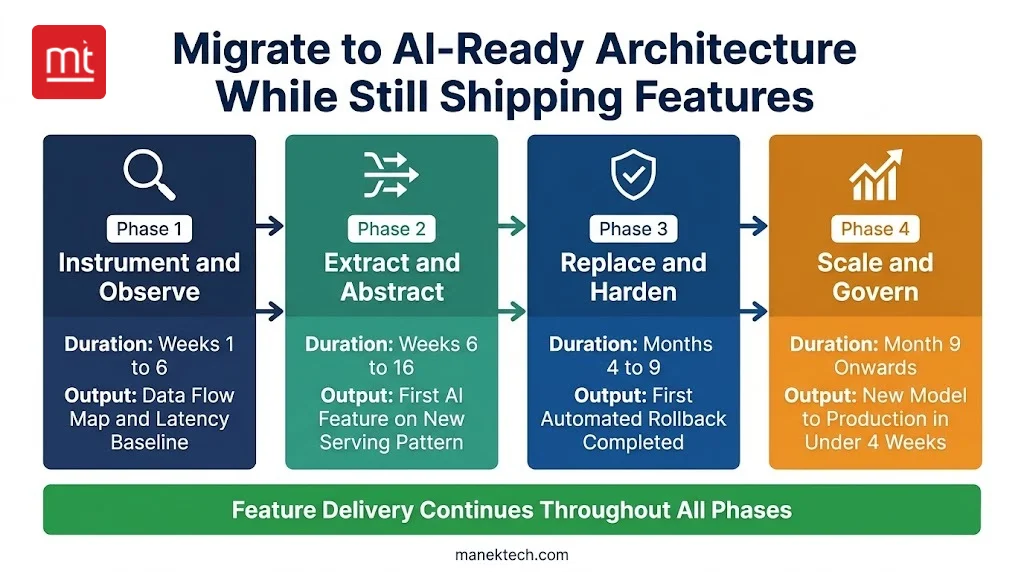
Phase 1: Instrument and Observe
Duration: Weeks 1-6 | Resource: 1 senior data engineer + 1 DevOps engineer
Understand what you have before you start making changes. This phase is read-only. Map existing data flows, identify every point where features are manually extracted, log what moves where and define latency budgets per user-facing AI flow. You can discover the migration issues that’s noticeable in phase 3 under pressure at this point itself.
Output deliverable: A complete data flow map. Baseline latency profile established per user-facing AI flow. |
Phase 2: Extract and Abstract
Duration: Weeks 6-16 | Resource: 2 ML engineers + 1 platform engineer + 1 data engineer
The architecture begins changing carefully in this phase. Extract the first feature pipeline into a versioned feature store. Deploy the async inference wrapper for a single feature. Implement semantic cache. Roll out 5-10% traffic only. Validate the training and serving parity before it advances. The goal here is to prove the pattern works on one feature before advancing with others.
Output Deliverable: First AI feature is live on the new serving pattern. Training/serving skew eliminated. Inference within P95 latency budget. |
Phase 3: Replace and Harden
Duration: Months 4-9| Resource: 2 ML engineers + 1 platform engineer + 1 security engineer
Apply the proven pattern across all the remaining ad-hoc feature extraction. Go live with model registry. Replace your manual releases with canary deployment. Implement and test rollback automation. Don’t assume it works; you must verify it. The success marker isn’t completion of migration. It is the first completed automated rollback that occurs without human intervention.
Output Deliverable: Canary deployment goes live with quality gates. First automated rollback completed and documented. Full production traffic on serving layer |
Phase 4: Scale and Govern
Duration: Month 9 onwards| Resource: ML platform team with 3-4 engineers + ARB process owner
By this time the architecture is proven. You must close the remaining gaps. Add prompt injection defenses and establish model access audit logs. Connect your feedback loop from production signals to the training pipeline. Formalize your architecture review board cadence. Team autonomy marks the success in this phase. A new ML team will ship a model from concept to production in under 4 weeks independently.
Output deliverable: Prompt injection defences go live. Production-to-training feedback loop connected. A new ML team ships model to production in under 4 weeks independently. |
Phase | Timeline | Key Activities | What You Ship | Resourcing | Risk | Success Marker |
Phase 1: Instrument and Observe | Weeks 1 to 6 | Add AI observability layer. log data flows. map feature extraction points, define latency budgets for each user flow | No new feature. Understanding existing system. | 1 senior engineer + 1 DevOps engineer | Low. Read only phase. No production changes | Complete data flow map, baseline latency profile defined per user flow. |
Phase 2: Extract and Abstract | Weeks 6-16 | Extract first feature pipeline into versioned feature store. Deploy async inference | First AI-powered feature on new serving platform. Limited rollout 5-10% traffic | 2 ML engineers + 1 platform engineer + 1 data engineer | Medium. Training/serving parity must be validated before traffic shift. | Training/serving skew eliminated. Inference set within P95 latency budget |
Phase 3: Replace and Harden | Months 4-9 | Migrate remaining ad-hoc feature extraction. Implement model registry and canary deployment. Add rollback automation. Complete observability coverage | Model update using canary with quality gates. First automated rollback exercise completed | 2 ML engineers + 1 platform engineer + 1 security engineer | High. Live traffic migration. Rollback paths should be validated before cutover | Bad model update. Automated rollback without manual intervention. Full traffic on new serving layer. |
Phase 4: Scale and Govern | Month 9 onwards | Implement prompt injection defences. Establish model access audit log. Build feedback loop from production to training pipeline | AI features on production scale. Internal teams shipping new models independently | ML platform team (3-4 engineers) + ARB process owner | Low. Governance and optimization phase. Architecture proven in production | New ML team ships model from concept to production in under 4 weeks. |
Your product roadmap doesn’t pause at any point during this migration process. Features continue to ship. The architecture keeps improving around them. By the end of phase 4, the team isn’t catching up. They start operating at a level the old architecture could never support.
Parallel Run with Traffic Shadowing: Replace of Strangler Fig
Parallel Run with Traffic shadowing is the most reliable migration pattern that works in practice. It is more precise and harder to misapply than generic strangler.
Here’s how it works. The legacy data extraction query is active in production. New feature store pipeline runs alongside, processing same events and writing to shadow outputs. That shadow output is then compared to legacy output on every request. Traffic shifts only when shadow and legacy outputs match within acceptable tolerance. This should occur for 30 consecutive days of production operation. Not just during sprint deadlines.
The legacy paths are decommissioned after the new path passes a formal quality gate. Not when the timeline says so or when teams are tired of running both systems.
Anti-pattern warning: Parallel run becomes a permanent state for teams that never set a decommission gate. Set an explicit gate at each phase review. Name the owner and set a date. Without both, parallel run becomes dual maintenance indefinitely. |
The Architecture Review Board: Governing Without Slowing Delivery
The ARB is a checkpoint, not a committee. Narrow down the scope or it will become a bottleneck, slowing down things it was meant to protect.
ARB sign-off is needed when introducing a new storage layer, changing model serving pattern or modifying prompt construction logic for customer-facing flows. It is also needed when adjusting inference latency budgets or workloads introducing data residency compliance requirements.
Model fine-tuning within existing infrastructure, prompt iteration within approved system prompt boundaries and feature engineering within existing pipeline patterns don’t need ARB sign off. These move at product velocity.
Meeting cadence is monthly, not weekly. Document the decisions that need ARB approval in the Architecture Decision Record before the review meeting. The ARB reviews decisions made in full context.
Stop Measuring AI Readiness by Model Accuracy: Measure It by Deployment Speed
Here’s a question you must ask your team. When was the last time a model accuracy improvement proved to be a bottleneck to shipping AI feature?
The most honest answer by teams would be never. The bottleneck is infrastructure. It is the data access, serving latency, incident recovery time and deployment process. Accuracy is a model problem. Delivery speed is an architectural problem.
Teams that are winning with AI solved their architecture problem first.
Why Model Accuracy Is the Wrong Primary Metric?
A 95% accurate model taking 6 months to deploy is less valuable than 90% accurate model deployed in 3 weeks and improving continuously through production feedback. This isn’t a hypothetical trade-off. It is the reality for teams experiencing infrastructure debt.
Deployment speed is a function of architecture, not model quality. Teams facing data pipeline friction, manual deployment processes and absent observability cannot iterate fast to close accuracy gaps through experimentation. The model stays at 90%. This is not because the team lacks skills. It is because the infrastructure doesn’t allow experimentation.
Here’s the measurement reframe.
Model accuracy tells you how good the model is today. AI-ready architecture tells you how fast you can make it better for the future. Measure time from model concept to production traffic. Also measure time to detect and recover from quality regression.
You should also measure percentage of AI features operating within defined latency budget at P99. These numbers indicate your competitive position today.
The AI Architecture Readiness Scorecard With Aggregate Scoring Model
Use this scorecard to assess your architecture’s current state. Aggregate score will tell you where to start, not where to aim. Every zero score is a specific architectural gap you must fix.
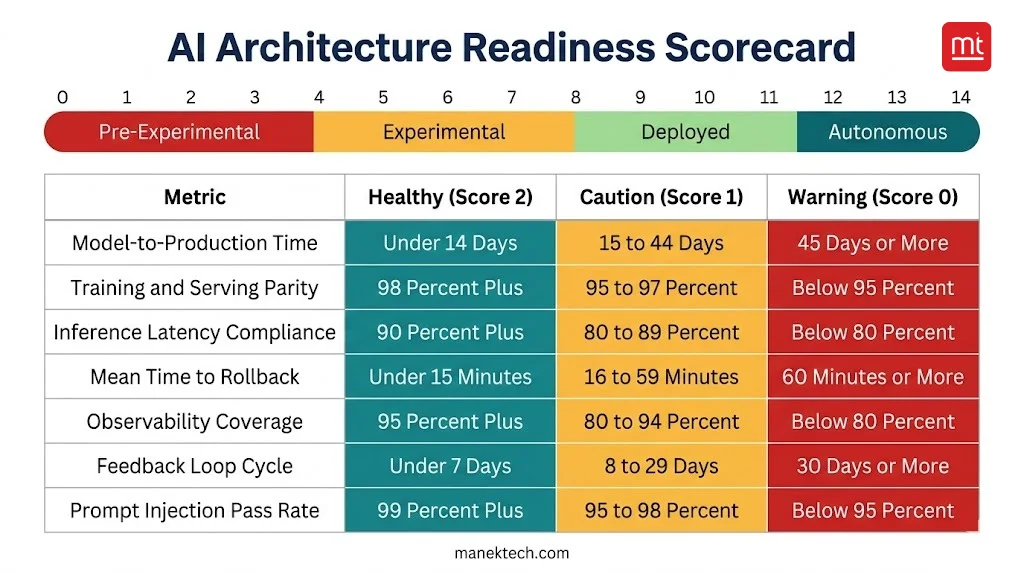
Score 2 = Healthy. Score 1 = Caution. Score 0 = Warning. Total possible: 14.
Metric | What it Measures | Score 2- Healthy | Score 1- Caution | Score 0- Warning |
Model-to-production Lead Time | Days from training completion to full production traffic | Under 14 days | 15-44 days | 45+ days, serving infras or approval process is the bottleneck |
Training/Serving Feature Parity | % of training features available identically at inference | 98%+ | 95-97% | Below 95%, feature store absent. skew is guaranteed |
Inference Latency Budget Compliance | % of AI flows meeting defined P99 latency target | 90%+ | 80-89% | Below 80%. Async patterns are absent. Inference layer undersized |
Mean Time to Model Rollback | Minutes from bad model detection to restoring stable version | Under 15 minutes | 16-59 minutes | 60+ minutes. Manual rollback. no model registry |
AI observability Coverage | % of model calls with structured logging | 95%+ | 80-94% | Below 80%. Degradation becomes visible. Incidents via support tickets |
Feedback Loop Cycle Time | Days from production signal to updated model in training | Under 7 days | 8-29 days | 30+ days. Pipeline not connected to training. Models go stale |
Prompt Injection Test Pass RAte | % of adversarial injection tests blocked | 99%+ | 95-98% | Below 95%. Critical security gaps for customer facing LLM features |
Note: All data is based on ManekTech AI architectural engagements and published MLOps benchmarks
Here’s a detailed interpretation of these scores.
- 12-14: Operational and autonomous maturity. Your architecture is AI-ready
- 8-11: Deployed maturity, completely functional. Gaps may cost you at scale
- 4-7: Experimental maturity. Significant architectural work needed before AI features can scale
- 0-3: Pre-experimental. Complete an AI architecture readiness audit before investing in AI.
Be honest with your scores. Purpose of this scorecard isn’t to produce a good number. It is to determine specific gaps that may be costing you delivery speed. A score of 6 with clear remediation plan is more valuable than a score of 10 built on generous self-assessment.
Key Insight: The most common scorecard pattern we have observed at intake is a 7 or 8 with zero on prompt injection test pass rate. It is also a 0 or 1 on feedback loop cycle. Teams have already invested in inference and serving. But, they haven’t closed the security and retraining loops. Both are fixable in phase 3 of migration model. Neither issue needs rebuilding what already works. |
The AI Maturity Progression
Your scorecard result places you somewhere on this maturity curve. Knowing which stage you are in helps you understand what to build next. This is equally important.
Stage | What it Looks Like | Architectural Signature | Typical Timeline to Reach |
Experimental | AI features are built ad-hoc. Models in notebooks. No production serving infrastructure | LLM API calls inline. No feature store. Manual deployment. No observability | Starting point for most teams |
Deployed | At least one AI feature in production. Basic monitoring. Manual rollback | Async inference wrapper. Basic logging. Single model endpoint. No canary routing | Months 1-4 of structured migration |
Operational | Multiple AI features. Automated quality monitoring. Model registry. Canary standard | Active feature store. Live drift detection. Automated rollback. Defined latency budgets | Months 6-12 of structured build |
Autonomous | AI features are shipped independently by product teams. Architecture enforces quality gates | Full observability. CI/CD for models. Prompt injection defences. Self-healing inference. | Months 18+ with sustained investment |
Most enterprise teams that come to ManekTech sit at experimental or early deployed stage. That’s not failure. It is the starting point for teams that were shipping features before infrastructure caught up.
The goal for the first 12 months of structured work is to reach an operational stage. AI begins compounding at this point with feature store in production, live drift detection and automated rollback.
Each new model benefits from the infrastructure the previous one was built on. This investment pays forward, not backward.
Autonomous isn’t the target for year one. It is the outcome of sustained and sequential investment across all four stages.
ROI Framework for AI Architecture Investment
Architecture investments are hard to justify without numbers. Here’s how you can build a business case.
ROI Factor | Calculation Basis | Conservative Estimate | Optimistic Estimate | Source |
Reduced data prep time | ML engineer hours saved per project by eliminating ad-hoc feature extraction | 15 hrs/project × 4 projects = 60 hrs/engineer/year | 30 hrs/project × 6 projects = 180 hrs/engineer/year | |
Faster model-to-production | Sprint cycles saved by automated deployment vs. manual release | 3 sprints saved × 4 releases/year = 12 sprint-weeks saved | 6 sprints saved × 6 releases = 36 sprint-weeks saved | ManekTech architecture engagement data |
Reduced incident cost | Hours saved by automated rollback vs. manual incident response | 4 hrs/incident × 6 incidents/year at senior engineer rate | 8 hrs/incident × 10 incidents/year | Industry SLA breach data |
Vendor cost comparison | Managed inference vs. custom-built at three scale tiers | Startup: USD 500/month managed vs. 80 engineering hours to build | Enterprise: USD 5,000/month managed vs. 800 hours to build and maintain | AWS SageMaker, Google Vertex AI pricing 2024 |
Conservative estimates across four factors justifies phase 1 and 2 investments in the first year itself. Optimistic estimates reflect teams with multi-model releases with high baseline incident rates. This justifies four-phase program.
If your team scores below 8 on readiness scorecard, the highest-ROI first step would be external architecture readiness audit. ManekTech conducts architecture audits as the first step in AI engagements.
You Do Not Need to Hire an AI Team: You Need to Architect Like One
When an AI initiative stalls, your first instinct is to hire. Often that’s a wrong move at the wrong time. Hiring before your architecture is ready does not manage delivery speed. It creates friction, delays output and increases repeated churns.
Three Resourcing Mistakes CTOs Make with AI Architecture
Mistake #1
Hiring the head of AI before your architecture can support AI at scale. The hire is good but your infrastructure isn’t ready. They spend six months advocating architectural changes needed. If these changes don’t happen fast enough, they leave and architectural issues still exist.
Mistake#2
Assigning AI infrastructure to an existing DevOps team without upskilling them. Container orchestration and model serving need different mindsets. Vector database operations aren’t same as database administration. Eventually, you get a system that is technically correct but architecturally incorrect.
Mistake#3
Purchasing an all-in-one AI platform before you understand workload. Platform lock-ins at the architectural layer is expensive to undo. Most all-in-one platforms work well for use cases they are designed for. They may constrain everything else.
What AI-Ready Looks Like in Team Structure
A centralized AI team doesn’t support AI-ready architecture. It becomes a bottleneck that slow down features and increase resentments. The AI team is blamed for velocity issues that are structural.
Centralized structure works for ML engineers embedded in product squads supported by dedicated ML platform team. The product squads own features. Platform team owns the infrastructure. The contract between them is an API. Product teams consume features from the feature store and deploy models via registry. Platform team manages the infrastructure these services work on.
Architecture decisions like vector store selection, inference pattern rationale and latency budget definitions are documented in Architecture Decision Records. ADRs live alongside the code and update when decisions change.
Build vs. Buy vs. Partner: AI-Ready Software Architecture Decision
Every architecture layer provides a build, buy and an option where partnering becomes the right call. This table helps you make the decision per layer without letting tool marketing do it for you.

Default position for most teams in the first 12 months is build what’s unique to your workload. Buy or use open source for everything. Partner when you need production-ready infrastructure faster.
Key Insight: Build vs buy decision isn’t permanent. Teams starting with pgvector and migrating to Qdrant at 800,000 vectors are making right call at both stages. Mistake isn’t choosing pgvector. It is choosing pgvector without a defined migration trigger |
Vendor Evaluation Framework
When shortlisting AI infrastructure vendors, these six criteria will help distinguish between production-ready and fit for demonstration vendors.
Criterion | What to Ask | Weight |
Latency SLA | P99 latency SLA? What happens on breach? | Critical; require clear SLA |
Data Residency | Can data stay in-region? Certifications (ISO 27001, SOC 2)? | Critical for regulated/GCC/EU |
Exit & Portability | How are embeddings, features, models exported? | High; assess lock-in risk |
Support SLA | P1 response time? Dedicated TAM available? | High (prod); Medium (experimental) |
References | Similar customer at same scale? | Medium; absence is a flag |
Roadmap | 12-month roadmap? How are changes communicated? | Medium; impacts long-term build |
Ask these questions before signing multi-year infrastructure contract. The vendors struggling with latency SLA and exit clause questions are the ones who contracts will cause issues when you outgrow them.
Readiness Signals
These checklists are a fast way to self-assessment. Go through both and answer them honestly.
Signs Your Architecture is AI-Ready
- A new ML engineer accesses clean, versioned feature data on day one
- Inference latency spike doesn’t impact unrelated user flows
- Bad model update is auto-detected and rolled back without incidents
- Product teams can ship impromptu changes without infrastructure deployment
- Every AI call is logged with context for debugging or compliance
Signs Your Architecture is not AI-Ready
- Teams recreate same features for training run
- Slow inference call blocks other user-facing requests
- Rollback needs redeploying previous code
- Model issues found via support tickets instead of monitoring
- No clear visibility into model version in production
Your architecture needs immediate remediation if two more items in the second list apply. Each gap maps directly to a layer in AI stack.
How ManekTech Architects AI-Ready Systems
All these sections point to one conclusion. The gap isn’t knowledge. It is execution. Knowing the right architecture is one thing. Building it under delivery pressure is another. This is how ManekTech approaches this gap.
How ManekTech Approaches AI Architecture
At ManekTech, we approach AI engagements with an architecture readiness audit, not a sprint plan with our AI developers. These audits map data flows, determine bottlenecks, set latency budgets and highlight decisions that drive delivery speed. All this happens before infrastructure is built.
In week one, ADRs define key choices like inference patterns, feature pipelines, observability and vector stores. These active documents guide all technical work.
Teams are structured. ML and platform engineers work together from day one. They build models and infrastructure in parallel to avoid production gaps.
AI maturity is tracked every 90 days using clear metrics, such as model-to-production time, observability coverage and rollback speed.
Most teams reach operational maturity within 9-12 months. Faster teams follow a full migration process without skipping early phases.
The AI Architecture Partnership Model
Partnership Element | ManekTech Standard |
Minimum Engagement | 12 months: quality shows over time |
Communication | Direct access to lead architect |
ML Platform Engineer | Assigned: owns feature store, inference, observability |
Quarterly Review | Tracks maturity, latency, observability, roadmap |
Implementation Model | Embedded team within client workflow |
Minimum 12-month is not a commercial position. It is an architectural reality. Feature stores live for two months hasn’t been tested against full-model retraining cycle. Canary deployment patterns running for 3 months isn’t tested against high-severity incidents.
Architectural quality is invisible at sprint timescales. They are measurable at quarter timescales. Engagement models are designed around it.
Client Architecture Outcomes
ManekTech’s audit identified training skew before production. The feature pipeline was redesigned early, avoiding 4-6 months of delay. System went live on a stable foundation within 10 weeks. ~CTO FinTech
An async inference layer replaced blocking calls. AI-related incidents dropped by 65%. P95 latency improved from 1.8s to 600ms within 3 months. ~ VP Engineering, HealthTech
Team moved from ad-hoc deployment to structured AI architecture. Operational maturity reached in 9 months. Model-to-production time reduced from 6 weeks to 10 days. ~ Technical Founder, eCommerce.
Starting the Right Conversation
Most teams ask the wrong question: “How quickly can you add AI to our product?” The right question is: “What does our architecture need to look like to support the AI features you want to ship in the next 12 months?”
One optimizes for speed. The other optimizes for survival. Architecture-first thinking isn’t slow. It prevents costly rebuild at scale.
Start with an architecture readiness audit by reaching out to our experts. Get a 40-hour risk-free trial to get started with architecture-first AI development.
Team Credential Signals
Our AI/ML engineers hold AWS ML expertise and Google Professional ML engineer certifications with years of average experience. We have implemented RAG pipelines, MLOps CI/CD workflows and real-time inference APIs.
The 2026 Scale Problem Is an Architecture Problem
The gap in AI delivery speed isn’t talent. It is architecture. Decisions made today will define it. Delaying would compound debt.
You don’t need full migration before shipping the next AI feature. Three decisions must be made now, before release.
- Define latency budgets for each AI-driven flow before choosing a model. The budget will filter feasible options
- Implement feature store or pipeline abstraction for retraining. This prevents training and serving skew before incidents occur
- Add observability to ever model call like logging, quality metrics and drift alerts
If you can’t detect 15% shift from dashboards, you will detect it from user complaints.
Executive Conclusion
Teams that redesign AI-readiness into their architecture in 2026 will spend 2027 shipping AI features. Team that don’t will spend 2027 resolving infrastructure debt while competitors are iterating.
These decisions aren’t optional. Feature stores, async inference, model registries and AI observability are baseline requirements for production AI.
If you are deciding where to get started, opt for an architecture readiness assessment. It costs less than early rework, giving you a clear roadmap.
ManekTech conducts architecture audits as the first step for every AI engagement. Connect with us to schedule your audit.
Frequently Asked Questions
Questions CTOs and founders ask us when evaluating AI architecture decisions.
#1. What is AI-ready software architecture?
It is a system where data pipelines, storage, inference services and observability are built for ML from the start, not as an add-on. Inference calls come with latency budgets. Training features match what is served at inference time. Model deployments are versioned with rollback. When something degrades in production, you find out from the dashboard instead of a user complaint.
#2. What is the difference between a feature store and a data warehouse for AI?
A data warehouse answers business questions. A feature store feeds your models. The key difference between the two is consistency. Feature store serves the exact same feature values during training and inference. This prevents training/serving skew, one of the most common and hardest to debug production failures. Most teams have a warehouse. Only teams running production AI need feature store.
#3. How does asynchronous inference improve AI application architecture?
Your user-facing threat waits for the model with synchronous inference. If the model is slow, the user waits. If it spikes, everything downstream will feel it. Async inference breaks the dependency. The requests are queued, models run separately and results return when they are ready. Latency spikes are also contained. The inference layer scales on its own and when model is under load, the rest of the app keeps running.
#4. How long does it take to migrate from a legacy architecture to an AI-ready architecture?
Most teams reach operational maturity within 9-12 months with feature store live, automated rollback fully working and full observability in place. However, this is the most important part. Migration runs alongside feature delivery. Not instead of it. You aren’t stopping to rebuilt. Instead, you are improving the foundation layer at a time when the roadmap continues to function.
#5. What are the most common AI architecture mistakes?
These five mistakes come up regularly. LLM API calls placed inline in synchronous request handlers without latency budget or fallback. Training models on ad-hoc SQL extractions wihtou a feature store, guaranteeing training skew at scale. Deploying model updates without registry or rollback path, exposing 100% production traffic to bad updates. Relying on standard APM tools that can’t detect model quality degradation. Treating AI security as RBAC standard without prompt injection defenses.
#6. Do I need a vector database for an AI-ready architecture?
Not always. You need a deliberate plan for semantic retrieval. At fewer than 500,000 vectors pgvector or another existing PostgreSQL instance is pragmatic starting point with a near-zero marginal cost. Beyond that scale or when you need sub-100ms similarity search, a dedicated store like Qdrant, Weaviate or Pinecone should be adopted. The decision isn’t which tool is better. It is about query patterns, SLA requirements and where workload is heading.
#7. What is the difference between AI-ready architecture and MLOps?
MLOps is the practice of managing model lifecycle operations like training pipelines, deployment automation and production monitoring. AI-ready architecture is the system design that makes MLOps practices implementable and scalable. Without the right architecture, your MLOps becomes a set of manual workarounds at every lifecycle stage. AI-ready architecture provides infrastructure contracts like feature store, model registry and observability layer that MLOps processes operate reliably
#8. How does AI-ready architecture affect cloud infrastructure cost?
AI-ready architectures reduce total cloud cost at scale using three mechanisms:
- Eliminating redundant feature extraction queries against production database can reduce compute load
- Semantic caching of frequent inference requests cut total model API call volume by 30-60% in high-repeat and query patterns
- Aysnc inference decoupling allows right sizing of inference instances rather than over-provisioning for peak synchronous load
Initial architecture investment is higher. Per-inference cost decreases as volume scales.

Nikhil Solanki
Mobile Lead
Nikhil Solanki has 10+ years of experience in App Development and currently works as the Mobile Lead at ManekTech. He is an experienced Mobile lead with a demonstrated history of working in Mobile's information technology and services industry.

Subscribe to Our Newsletter!
Join us to stay updated with our latest blog updates, marketing tips, service tips, trends, news and announcements!















